When a packet is sent "into" the Internet, it passes through a "local" network to the first router -- sometimes called a "gateway". This router examines the packet's destination address and decides which router, of all those it is directly connected to, it should forward the packet onto for its next hop. The process is repeated at the next router, and so on, until the packet reaches its destination.
The definition of how this all works, the format of packets, how routers behave, etc, is defined by the Internet Protocol (IP). In general, a protocol is a set of rules together with a set of data structure definitions (the packet formats) which define how a set of operations (in this case, Internet packet delivery) is carried out.
Two other disasters can befall delivery: a sequence of packets may not arrive in the same order in which they were sent, and a packet can even become duplicated during delivery -- that is, the same packet is received twice.
However, note one important fact -- in this context, unreliable doesn't mean "no good", or "poor quality". It simply says that the delivery system may fail to deliver a packet correctly. In fact, most packets do get delivered correctly. This is because the second design concept for the Internet is best effort -- under normal operation, it works. Sections of the network should only exhibit unreliability under abnormally heavy loads.
A final design concept, that of connectionless IP packet delivery, will be discussed later.
We introduce the concept of edge systems, or (to use the traditional term) hosts. These are (in general) computers which are connected to the Internet -- in other words, everything that isn't a router. Your desktop computer is an edge system, our main departmental server ironbark is an edge system as are most other servers which you could name.
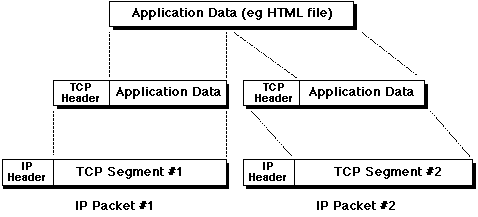
TCP builds the "payload" of IP packets, by slicing application data into chunks small enough to fit, with a little extra administrative overhead (ie, a TCP header), into a single IP packet. These are called TCP segments[1], thus:
[1] more formally segments are called "Transport Protocol Data Units" or TPDUs. No one ever uses this term in relation to the Internet, though.
In normal operation a TCP entity running on an edge system sends a segment, containing application data, to a remote TCP entity. The remote TCP receives the segment, and returns a special acknowledegement (ACK) segment back to the originator. Upon receipt of this ACK, the orginating TCP knows that the data has been received correctly.
If a packet, containing a TCP segment, fails to be delivered then no ACK will be received. Eventually the originating TCP will timeout (decide it has waited too long) and re-send the segment. With luck, and given a sufficiently low packet loss rate, the second attempt will be successful. If not, the sender can timeout again, and once again resend the segment. Thus all data will eventually get delivered, although TCP does not guarantee how long it will take.
The connection is actually initiated by an Application Process (or program in execution), which requests TCP to establish connection to another application process running on a remote edge system. In general, the remote process is already waiting for connections.
Ports are the addresses of TCP. We can think of them as an adjunct to IP addresses: the IP address specifies a particular computer, whereas the port number specifies which process, running on that computer, we wish to communicate with.
Terminology: A process which is waiting for connections "at" a particular port number is said to be a server process. A process which initiates a connection to a server is called a client process. It's important to note the specific meaning of these words in the context of TCP/IP.
The protocol section of the URL specifies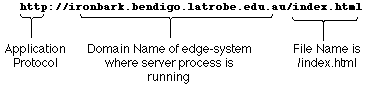
HTTP,
the HyperText Transfer Protocol. This protocol is associated
with the well-known port number 80 -- that is, when we connect to a server
process at port 80, we expect to "talk HTTP". The domain name of ironbark is just an
alternative way of specifying its IP address, which is actually
149.144.21.60 -- see later for more on this. And the desired
file on ironbark is (note Unix terminology) "/index.html".
In the simplest version of HTTP (HTTP/0.9 - circa 1993), the client (ie, the Web browser) sends a line of plain, ASCII text to the server process, thus:
GET /index.html /index.html, also in
ordinary plain (ASCII) text. Finally, the browser process interprets the HTML
markup in the returned file, and displays it to the user.
[2] We shall return to the topic of well-known services later, but basically all of the server port numbers below 1024 are reserved for generally agreed services.
Notes: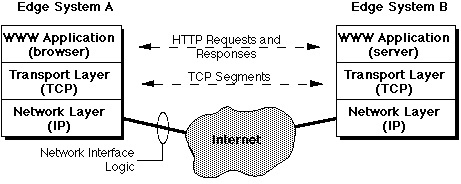
The telephone system is circuit-based. A telephone call reserves a channel which can carry continuous speech, reliably, in both directions simultaneously. This is immensely costly in resources: the network must be engineered to provide perfect reliability once a call (or "circuit") has been established. For these reasons, phone calls tend to be expensive. On the other hand, the "end-user" equipment is incredibly simple -- a telephone[3]. In the case of the the telephone system, all of the complexity is in the network, The edge-systems are trivially simple.
The Internet reverses this. The network (or delivery system) is simple, and doesn't guarantee anything, except a high probability of packet delivery. The complexity is in TCP, which exists only in edge-systems. The edge systems themselves are poweful computers -- sufficiently powerful, at least, to run TCP. We can say that the end-user provides the complexity, whilst the Internet provides a basic service. We could say this this is the last Big Idea for this lecture.
It's also interesting to compare the Internet model with other, older network structures. For example, the AustPac X.25 "Packet Service" was a data transfer system available in Australia many years before the Internet. It offered reliable delivery at the network level, but was very, very expensive -- because the network core was complex. Its commercial success, whilst quite good by the standards of the day, was never, ever going to approach that of the Internet.
[3] We're talking about "Plain Old
Telephone Services" here, of course. The situation changes dramatically if we
were to include mobile, cellular telephone systems, where the handset is also
very complex.
