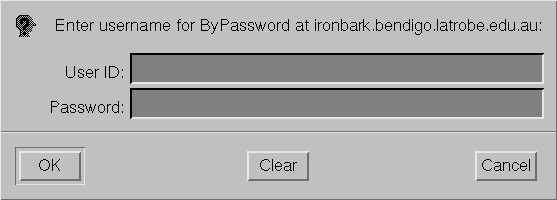
An initial HTTP attempt to access a "password protected" Web page of this type (without providing suitable "authentication" information) will generate an HTTP error message together with a Web page which explains the nature of the error. Typically the response headers will contain:
In HTTP/1.0, only theHTTP/1.1 401 Authorization Required Date: Wed, 17 Mar 2004 01:17:56 GMT Server: Apache/1.2.6 WWW-Authenticate: Basic realm="ByPassword" Last-Modified: Mon, 15 Mar 2004 00:43:51 GMT ....etc....
Basic
authentication method was available, as used in this example.
Upon receiving this error, the Web browser will normally pop up a dialog box
similar to the above, collect a user-ID and password from the user, and then
retry the request with an additional "Authorization: "
request header containing the additional information.
Authorization Request HeaderLet's use as an example, a page for which the username is
"student", password "student" -- pretty
typical :-). The concantenation is thus
"student:student". We can use the Unix commandline base64
program mimencode to encode the data, (it encodes to
"c3R1ZGVudDpzdHVkZW50") so that the request header will look
something like:
This, of course, begs the obvious question -- why on earth do they do this? The obvious answer is "for security reasons" -- to deter casual network snoopers who might be observing traffic, watching for passing user-IDs and passwords. We are left wondering...GET /subjects/int21cn/test/index.html HTTP/1.0 Authorization: Basic c3R1ZGVudDpzdHVkZW50 ....etc....
A browser which is "cookie-enabled" will normally[1] store this name/value pair, and future requests to the same server will contain an additional request header, thus:HTTP/1.0 200 OK Set-cookie: myname=myvalue ....etc...
Cookies are extensively used in Web session management, which is discussed later in the unit.GET /somefile.html HTTP/1.0 Cookie: myname=myvalue ....etc...
[1] In fact, cookie operation is
rather more complex than we discuss here -- for example, the
"Set-cookie: " header can take several additional parameters
(which affect how the cookie is interpreted), and the behaviour of browsers with
respect to cookies can be changed by the end-user.
A form in HTML is an area of a Web page which is used to gather input from a
human user. The information which is gathered can then be returned to the page's
owner using a SUBMIT action.
The form is, as expected, delimited by a <FORM> and
</FORM> markup pair.
The <FORM> markup has two important attributes:
ACTION
METHOD
ACTION URL is accessed.
There are two methods, GET and POST.
<FORM ACTION="http://ironbark.bendigo.latrobe.edu.au/cgi-bin/myprog" METHOD="GET">
INPUT tags. Each INPUT tag has an
associated TYPE attribute.
For example:
This<INPUT TYPE="TEXT"
INPUT type can take several further
attributes, eg:
In a browser, this would be presented as a (scrollable) textbox, 20 characters wide (but able to accept 64 characters of input).<INPUT TYPE="TEXT" NAME="Name" MAXLENGTH="64" SIZE="20">
There are several other INPUT types:
TYPE="PASSWORD"
TYPE="CHECKBOX"
TYPE="RADIO"
TYPE="IMAGE"
TYPE="HIDDEN"
TYPE="SUBMIT"
TYPE="RESET"
SELECT
OPTION markup tag, which can take a couple of
extra attributes.
TEXTAREA
ROWS and
COLS and can have a NAME attribute and
an initial value.
...or simply "URL-encoded". In this format:application/x-www-form-urlencoded
+" character. This is a hangover from an older format and
is normally, but not universally, used -- see next point.
%HH, where the H
characters are the two hexadecimal digits of the byte. Sometimes the space
character is also sent in this format, as "%20", instead
of as "+".
name=value, with
each name-value pair separated by the "&" (ampersand)
character.
METHOD=GET and
METHOD=POST.
GET
GET request is issued to the ACTION
URL specified in the <FORM> markup tag, with the
urlencoded form information appended after a separating
"?" character. This can generate very
long URLs.
POST
POST transaction is performed. The "body" of the
transaction contains the urlencoded form data, as a single long line of text.
The POST transaction is directed at the URL specified in the
ACTION attribute of the <FORM>
tag. In "real life", GET and POST methods
are used pretty much interchangeably, depending on the programmer's or system
designer's preference.
GETSubmit button, you should pay close attention to two things:
? character. The HTML for our FORM looks like:
This is rendered in your Web browser as:<FORM action="/subjects/int21cn/cgi/L06CGIa.cgi" method="GET"> info1: <INPUT type="text" name="info1" size="20"><br> info2: <INPUT type="text" name="info2" size="20"><br> <input type="submit" value="Submit"> <input type="reset" value="Clear Form"> </FORM>
Try it!
POSTIn this case, we're going to try something different -- the CGI program which is the target of this Form is going to show us the actual HTTP request as it was received[2].
Again, try it.
[2] Actually, it's a "reconstructed" version of the HTTP request: not all request headers are necessarily shown. But it's close enough for our purposes!
When a user clicks the SUBMIT button on a form, the HTTP
server starts up the specified CGI program, and makes the form data available to
it.
From a programming perspective, the difference between
GET and POST is the way in which a CGI
program receives the form data. If the method was GET, the
information is usually obtained by examining the contents of an
environment variable (usually called
"QUERY_STRING) containing the URL-encoded form data. Other
environment variables contain additional useful information.
If the method was POST, the CGI program usually receives
the form data on its standard input stream, with any extra
stuff obtained, as before, from environment variables.
CGI programs can, as a rule, be written in any language (compiled or interpreted) supported on the system running the HTTP server.
On Unix servers, they are commonly written in Perl,
C or as Bourne shell (/bin/sh) scripts.
A CGI program (almost) always generates (to standard output) a Web page which is returned to the browser, in addition to any other effect.
