Lecture 7: Internet Applications #3.3: HTTP/1.1
A nice short lecture
this time -- we tie up a few last topics in HTTP.
HTTP/1.0 Performance Issues
HTTP/1.0 has been criticised
for poor performance and lack of scalability. There are several aspects to this:
- HTTP/1.0 opens a new TCP connection for every single transaction. For
example, if a Web page contains 10
<img ...> images,
HTTP/1.0 must open a total of 11 TCP connections -- one for the original page,
and 10 for the images. Problems which arise from this include:
- There can be a moderately long overhead in initial connection
establishment due to round-trip delays.
- TCP initiates connections using the so-called "slow start" algorithm.
This is necessary for proper operation, but is very inefficient for short
transfers -- TCP typically takes 10 to 20KB of transferred data to get "up
to full speed". Both of these can cause HTTP/1.0 browsers to seem really
slow.
- TCP is required to maintain "state" information about closed connections
for 240 seconds, to ensure that stray packets from old connections won't be
interpreted as valid data by a later connection. When a server is handling a
large number of connections, this can require huge buffer space, and is very
inefficient.
- HTTP/1.0 has limited support for caching.
Because of these aspects, HTTP 1.0 is gradually being replaced
by HTTP/1.1.
(rfc2616).
HTTP/1.1 Basics
HTTP/1.1 (rfc2616) is now in
widespread use. It extends the older protocol in a number of areas, notably
persistent connections/pipelining and support for
caching.
To implement Persisent Connections, HTTP/1.1 introduced a
new request (and also response) header called "Connection:".
This can take two values: "close" (which means that this is
not a persistent connection) and
"keep-alive", which means that the TCP connection is held
until either side sends a "Connection: close" header,
indicating that it wishes to terminate.
The browser can utilise a persistent connection by sending multiple requests
over the connection without stopping and waiting for each them to be satisfied
before sending the next -- the reponses are "in the pipeline". Similarly, the
server can respond with responses sent one after another another. This is
possible because each request can be unambiguously identified, as can the
responses, using the "Content-length:" headers. The huge
wins here, obviously, are that there's no delay opening multiple TCP
connections, and the slow-start algorithm has time to get up to full speed.
Web Caching
The World Wide Web has been spectacularly successful -- so
successful that a huge proportion of Internet traffic is HTTP, ie Web pages and
related objects such as images. Caching is a technique whereby
copies of popular objects are kept in strategic locations, and supplied in
lieu of the originals, saving huge amounts of traffic on the "backbone
networks".
The Conditional-GET operation seen earlier allows support
for caching at the browser level -- that is, the browser can
keep a local copy of an object and check if it's up to date before displaying
it. Two additional features of HTTP/1.0 were:
- The
Expires:
- response header was used to indicate that an entity had a limited
(specified) "lifetime". This permits finer control over the Conditional-GET
operation. It takes an Internet-standard date/time string as its value.
- The
Pragma: no-cache
- response header has an obvious meaning: this entity should never be stored
in a cache.
- Note: the (non-standard)
Refresh:
- response header can be used (in some browsers) to force a reload of an
entity.
Additionally, HTML "<META HTTP-EQUIV=..." tags
can include "equivalent" response information in the
<HEAD> section of an HTML document. The browser
may regard this as being equivalent to the corresponding HTTP response
header.
Proxy Caches
A proxy server is an HTTP server which fetches Web objects
(pages, images, etc) on behalf of its clients. Proxies normally cache all
"cacheable" reponses, so that if an entity is stored locally, it is returned
instead of sending a request to the originating server. Such shared
caches can significantly reduce an organisation's "download volume", as
well as give significant performance improvements to the end-user.
Requests to a proxy server are always specified as full URLs, so the first
line of a typical GET request now looks like:
GET http://www.bendigo.latrobe.edu.au/index.html HTTP/1.0
....other request headers...<newline><newline>
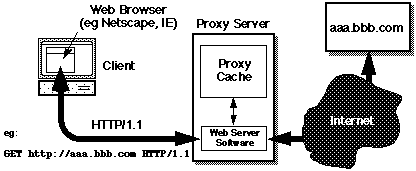
Whilst proxy servers
(and caches) were described in HTTP/1.0, the rules as to how caching should be
controlled were unspecified.
Cache Control Mechanisms in HTTP/1.1
HTTP/1.1 introduced a new
Cache-Control: header which significantly improved the
operation of both private (browser) and shared (proxy) caches. This response
header is complex: it has many, many possible combinations of value. Some common
examples include:
Cache-Control: public
- This entity is always cacheable, even in circumstances where it may not be
obvious (eg, in response to a request with an
Authorization: header.
Cache-Control: private
- The reponse is not to be cached in proxy caches, and is
intended for the use of the end-user alone. The response may
be cached at the end-user browser.
Cache-Control: no-cache
- Obvious. Don't cache this reponse anywhere. The
no-store directive is even more restrictive.
Cache-Control: max-age=3600
- Specifies a time, in seconds, after which the entity becomes "stale". The
s-maxage variant specifically refers to proxy (shared)
caches. Both of these are commonly combined with re-validation options, to
give (for example):
Cache-Control: max-age=3600, must-revalidate
- After 3600 seconds, the freshness of the entity must be checked at the
originating server.
Entity Tags in HTTP/1.1
The "Entity Tag" is new in HTTP/1.1 and is used
to indicate that two (perhaps apparently unrelated) resources are in fact the
same. For example, requests for each of the two Web pages:
http://ironbark.bendigo.latrobe.edu.au/subjects/int21cn/news.html
http://ironbark.bendigo.latrobe.edu.au/subjects/int31bcn/news.html
Both return the same Entity Tag header:
ETag: "1cc30e3-88e-404e6d9b"
The client can use an
If-None-Match: "1cc30e3-88e-404e6d9b"
request header
with a GET request to specify the version of the object which it already has.
This is a significant improvement over the HTTP/1.0 "Conditional-GET" --
although not all entities are (by default) generated with Entity Tags.
You can discover lots more about HTTP/1.1 at: http://www.w3.org/pub/WWW/Protocols/Specs.html

Copyright © 2004 by Philip
Scott, La Trobe University.
