Lecture 24: Data Formats and Encoding -- A Philosophy Lecture
Reflections on Data Encoding
Compare:
- Classic Internet Application Protocols
- Protocol messages usually lines of printable ASCII text,
using the telnet NVT convention for line endings. Data is
either textual (hence transmitted as Telnet NVT lines),
encoded into textual form (eg, Base64 for email attachents)
or simply transmitted as binary (eg, images in HTTP) -- no
generic rules apply across all protocols.
- SNMP-based Network Management
- Data and protocols are both described using ASN.1,
encoded using the TLV-style BER for transmission -- a
binary format. The entire PDU (data and "header information")
is a single BER entity. Note, incidentally, that ASN.1 technology is in
wideapread use other than in network management; eg, in LDAP,
X.500 (and related), Microsoft NetMeeting and in many
industrial applications.
Both of these formats exemplify a principle whereby the
protocol message is encoded into a standardised or
canonical form for transmission. What "goes over the wire" is
in the same format, regardless of the type and characterictics of each of the
machines involved in the transfer[1].
This is a Big Idea.
[1] There are alternatives to this:
we already seen a technique (way back in the telnet lecture) generically called
terminal emulation, whereby the sender of the data converts it
to the specific format expected by the receiver before sending. The other
approach is called (in some circles) receiver-makes-right. Here
the receiving software, knowing the source of the data, converts it to its own
format before proceeding. This obviously fails if the source can't be
determined!
Parsing
ASCII text-based protocols have the advantage of human
readability, which has aided the debugging and development of these
protocols. Also, many other data types can easily expressed in ASCII -- for
example, numeric data: eg, the ASCII string "2529" is
clearly an integer. Note, however, that even such a simple system has potential
pitfalls: think of the textfile conventions of Unix systems,
PCs and Macs vis-a-vis the telnet NVT "line-of-text" convention used in
these protocols.
Protocol messages in these classic Internet application are structured to
conform to a grammar -- a set of syntax rules.
The receiver of such a message has to parse it to discover its
meaning. This can be compared to the process whereby (eg) a Java source file is
compiled to a byte-code equivalent. The problem here is that
writing a parser is (still) considered to be a difficult programming problem,
and developers tend to try and avoid them if possible...
In contrast, an ASN.1/BER bytestream can be interpreted
using (in principle, at least) a somewhat simpler pattern
matcher. Such software is, in general, easier to write -- it can be
written using a "Finite State Machine" model, or could even be as simple as a
sequence of nested IF-statements. The downside is a protocol that can't be
tested using "human-readable" messages. TANSTAAFL.
Document Formats -- XML
We have concentrated, so far, on
protocol formats, but the data (or document) is also
interesting. For example, the (usually) ASCII HTML document is the basis of the
World Wide Web. HTML is a curious mixture of structural (or
semantic) markup, and markup elements used for in-line
presentational formatting. For example,
<h2>Header</h2> is clearly a structural markup,
whereas
<b><i>important text</i></b> is
(generally speaking) simply an indication of how the author would like the text
displayed.
HTML has evolved (via mechanisms such as Cascading Style Sheets (CSS)) into
the far richer XML (eXtensible Markup Language). In XML, the
details of both the meaning of the markup tags, and the presentational aspects
of the document have been separated from it. The document itself contains only
semantic (or structural) information. Conceptually we have the
notion of "Document as Database"
XML can be considered as a document-level canonical form. It has already been
used extensively in the Web, both as an adjunt to HTML and as a replacement --
modern browsers can already process XML documents using associated
XSL style sheets. More importantly, it is becoming clear that
more complex "Web Services" can, and will, be based on XML, see
later.
Background: Client-Server Programming with RPC
Until now, this unit has
only looked at (socket-based) protocols where the details of the protocol are
visible to the programmer. An alternative paradigm is that of the Remote
Procedure Call (RPC). In this model, a programmer (using an
imperative or procedual programming model)
thinks of a service on a network server as though it were a
sub-routine (or procedure, or
function[2])
in almost exactly the same way he/she thinks of a local sub-routine.
An RPC application is built (compiled), as usual, but with external (remote)
procedures replaced with stub procedures. The RPC system
arranges for the stub procedure to transparently send network messages to the
remote procedure, and receive returned values. Thus development of networked
applications is, in theory at least, not harder than development for a single
machine. The Unix RPC system (originally developed at Sun Microsystems) uses a canonical
form called XDR (eXternal Data Representation) data
encoding system for sending data across the network. It is quite a complex
specification: we will examine how one data type -- the integer
is handled.
[2] "Sub-routine"
is an historical generic term for a re-usable code-segment with formally
specified parameter passing conventions. The term
procedure was used for the same thing in Pascal, and
function in C.
Example: Integers in Unix RPC
We assume that an integer is 32 bits (4
bytes) in length. There are (basically) two ways in which an integer can be
stored in the memory of a computer: with the Least Significant
Byte in the lowest numbered address (so-called
Little-Endian format), or with the Most Significant
Byte at that position (Big-Endian). The Intel (and
compatible) range of processors is Little-Endian, as were the Digital range of
CPUs, and virtually all others (past and present) are Big-Endian.
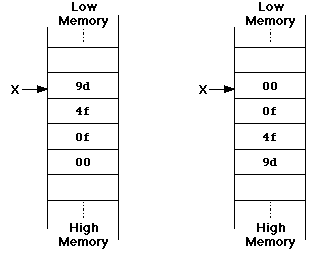
Take, for example, the integer
1003421dec
(000f4f9dhex). We assume that this integer is
stored at address X in memory. In the Little-Endian storage,
shown at left, the byte at the "address of" the integer has value
9dhex. In Big-Endian storage, shown at right, the
byte at the "address of" the integer is 00hex.
Software which desires to send (as raw bytes) such an integer as a parameter
to a remote procedure cannot simply read the bytes from memory and transmit
them, because the remote machine might use a different byte-order. In
XDR, the solution is to (transparently) convert integers from
their native format to Big-Endian format for transmission, and
transparently convert them back at the other end to the appropriate native
format. Hence, two non-Intel machines will incur no "translation overhead",
whereas two Intel machines communicating will be required to convert the order
at each end of the communications.
It will be readily seen that, as mentioned, XDR uses canonical
forms for data transmission. More importantly, the required conversions
occur within the RPC sub-system, so the programmer never needs to be
aware of them. Their operation is transparent.
Extended RPC: "Distributed Object" Programming Models
The emergence of
Object-Oriented Programming (OOP) -- particularly in languages
such as C++ and Java -- changed the way in
which programmers thought about RPC. Instead of executing a remote
procedure/function, the conceptual model became that of "networked objects", and
thus invocation of their object methods across the network.
The three major "frameworks" in this space have (historically) been:
- CORBA (Common Object Request Broker Architecture)
- Developed by the Object Management Group
(OMG), this framework was the first attempt to create a "distributed
object" environment. Based on the idea of an "Object Request
Broker", it uses a protocol called the "Internet Inter-ORB
Protocol (IIOP)". Available for most platforms.
- DCOM
- This framework was developed by Microsoft, and is specific to their
platforms and language development environments, although Java is supported,
and third-party companies ahve developed implmentations for other platforms.
The "Object Remote Procedure Call (ORPC)" protocol on which
it's based is derived from the older DCE specification, a competitor to Sun's
original RPC.
- Java/RMI
- Sun Microsystems has developed this
system to support its "Java Everywhere" model of programming -- only supported
for the Java language from release 1.1. The underlying protocol is called
"Java Remote Method Protocol (JRMP)" and was (apparently)
developed from the original Sun RPC.
Each of these frameworks (and their underlying protocols) is
based on the idea of serializing the objects to be transferred,
transparently to the developer. He/she does not need to know
the details of how the system is implemented, or what it's doing "underneath".
The mappings from a program's (system's) internal data structures to (and from)
what's sent over the network is automatic.
Future RPC: Web Services with SOAP & XML-RPC
The XML data model is
rich enough to represent virtually any data object. Initially, a group working
at Microsoft came up with the idea of doing Remote Procedure Calls using XML as
the "serializing" technology. Their original work has spun off to become the "XML-RPC" project, which has
the aim of "...remote procedure calling using HTTP as the transport and
XML as the encoding. XML-RPC is designed to be as simple as possible, while
allowing complex data structures to be transmitted, processed and
returned.". XML-RPC is based on HTTP's POST request for the "procedure
call" and an ordinary HTTP response to return the results.
A separate project team, at Microsoft, decided to extend the basic idea of
XML-based RPC to a much more elaborate protocol, calling it the "Simple Object Access Protocol
(SOAP)". It has been submitted to W3C as a proposed standard. It can run over
HTTP or SMTP (?), and allows arbitrary objects to be encoded (or serialized).
SOAP has the backing of several influential companies (Microsoft, IBM, etc).
The (recently invented) expression "Web Services" is based
on SOAP, and describes a range of proposed "Business-to-Business" XML-based
services running over HTTP (port 80). Perhaps the most significant aspect of
SOAP-based Web Services is that both the protocol (usually HTTP) and the core
language (XML) are public standards, and are well understood. Even more
significant is that SOAP builds on the knowledge gained from a decade of "The
Web", and from this perspective alone is likely to succeed.
So What's Wrong with XML?
Not much. Except that it general it creates
BIG datasets. In fact, the XML spec states: "Terseness in
XML markup is of minimal importance". Some typical numbers: a colleague's
recent ASCII database dump of about 9MB turned into 25MB in XML for network
transfer. Why is this a problem?
An oft-quoted(?) technology axiom states (approximately): "Bandwidth
and batteries do not follow Moore's Law". That is, whilst CPUs roughly
double in performance every 18 months, other more "mundane" technologies don't.
Some examples:
- transferring data to "smart cards" and other embedded devices with
severely limited power, memory and I/O capacity.
- Transferring data to mobile devices. It's obviously more profitable if a
carrier can squeeze more information into the same airtime. It's also better
for battery life if airtime is minimised.
In other words, compactness in data encoding will always be
important in networking.
Compact Encodings
So what's the best way to encode compact data?
- Answer #1:
- Compress the XML before transmission? Wrong. Why? Unless
the document is large, typical compresion algorithms (eg
gzip) actually make the data bigger. And lots of CPU power
is needed at the receiver to decompress.
- Answer #2:
- Ignore the problem. Unfortunately this is wrong too. The problem is that
in XML the recipient is required to "parse" (a slightly
different meaning of the word than previous) the document to extract
information. This can be compared to the traditional RPC approach where the
RPC libraries map information directly to "internal" data structures. Parsing
is a heavy consumer of CPU, and hence battery power. Note that there isn't
universal agreement on this point!
- Answer #3
- Invent a standardised way of converting an XML entity into a new (compact)
form for transmission. The XML
Binary group is working on this possibility.
- Answer #4
- Use an existing compact binary encoding, of which the
best known and understood is probably ASN.1/BER!
Montagues and Capulets: ASN.1 and XML[3])
One
of the fascinating research efforts in this area has been integrating the ASN.1
"view of the universe" with XML. Consider this:
- The modern way to describe the structure (and meaning) of an XML document
is by XSD -- XML Schemas. An XSD is written
in XML.
- The ASN.1 language is, of course, a schema language too.
In fact, it turns out that it's possible (and for simple cases, trivial) to
automatically convert an
XSD into an ASN.1 definition, and(?) vice-versa.
The ASN.1 community is now suggesting that ASN.1 is a better
schema language than XSD. A document/data entity which is described using ASN.1
can be automatically mapped to textual XML for network transfer, and an XER (XML Encoding Rules)
standard is now available. Alternatively, it can be encoded using BER (or, more
likely its successor DER) into a compact binary format where this is needed. The
Fast
Web Services initiative is now focussing commercialising this.
[3] The Montagues and Capulets were
the two feuding families in Shakespeare's play "Romeo and Juliet".
The comparison was (apparently) first made in this
paper (caution: link is MS Powerpoint document).
References
The ISO
8859 Alphabet Soup
Google's
Component Frameworks -- Comparison and Review Page
A Detailed Comparison of
CORBA, DCOM and Java/RMI
OMG Home. See
also CORBA Home.
RMI tutorial. from Sun. See also here.
Microsoft's COM Technologies page.
Doesn't display in my copy of Netscape 4.
XML, Web
Services, and the .NET Framework
SOAP vs. DCOM &
RMI/IIOP
XML-RPC vs.
SOAP
Google's
Web Services -- SOAP Page. The "Categories" and "Related Categories" lists
of useful useful links are good here too.
More about SOAP (and related protocols)
than you're ever likely to need...
XML-RPC Home Page
The tutorial for this
lecture is Tutorial
#24.
 [Previous
Lecture] [Lecture
Index] [Next
Lecture]
[Previous
Lecture] [Lecture
Index] [Next
Lecture]
Copyright © 2004 by Philip
Scott, La Trobe University.
